Olá Pessoal,
Dando sequência as nossas publicações sobre Ansible, e como já comentei com vocês que estou pegando alguns exemplos que de fato são situações que nós Engenheiros de Rede acaba vivenciado para executar esse tipo de trabalho em nosso dia a dia, ou seja, venho com a pergunta. Vocês já receberam aquele Excel ( .csv ), para de fato fazer algumas alterações em seus equipamentos?
Se sim, acredito que você está no caminho correto, pois hoje, venho com mais um exemplo que vamos fazer as preparações para tratar nossos dados e posteriormente criar nossos arquivos de configuração que serão aplicados em nossos equipamentos Cisco ( IOS ).
Vale lembrar, para que seja efetivo nossa Automação precisamos ter um inventário consolidado, onde as informações relacionadas ao nossos equipamentos devem ser coerentes para futuro crescimento de nossa infra-estrutura. Se você ainda não acompanhou os posts anteriores, recomenda-se ler esses tópicos sobre Ansible.
Como vocês podem observar vamos tratar nossos dados via um arquivo ( .csv ), que de alguma forma são valores/informações populadas através de outras fontes ( ferramentas, pessoas, etc ). Em nosso exemplo, estou colocando diversas informações que a principio vocês possam não entender, mas no decorrer de nossos posts isso fará sentido para o entendimento correto e as opções que podemos criar em nossa automação.
inventory_hostname,DHCP,dhcp_exclude1_start,dhcp_exclude1_end,dhcp_network,dhcp_netmask,dhcp_gateway,new_hostname,id_loopback,ip_loopback,mask_loopback
R1,true,1.1.1.9,1.1.1.10,1.1.1.8,255.255.255.248,1.1.1.1,R1_floor1,10,10.10.10.1,255.255.255.255
R2,false,1.1.1.9,1.1.1.10,1.1.1.8,255.255.255.248,1.1.1.1,R2_floor1,10,10.10.10.1,255.255.255.255
R3,false,1.1.1.9,1.1.1.10,1.1.1.8,255.255.255.248,1.1.1.1,R3_floor1,10,10.10.10.1,255.255.255.255
R4,false,1.1.1.9,1.1.1.10,1.1.1.8,255.255.255.248,1.1.1.1,R4_floor1,10,10.10.10.1,255.255.255.255
R31,true,1.1.1.9,1.1.1.10,1.1.1.8,255.255.255.248,1.1.1.1,R31_floor1,10,10.10.10.1,255.255.255.255
R32,true,1.1.1.9,1.1.1.10,1.1.1.8,255.255.255.248,1.1.1.1,R32_floor1,10,10.10.10.1,255.255.255.255
R5,false,1.1.1.9,1.1.1.10,1.1.1.8,255.255.255.248,1.1.1.1,R5_floor1,10,10.10.10.1,255.255.255.255
R6,true,1.1.1.9,1.1.1.10,1.1.1.8,255.255.255.248,1.1.1.1,R6_floor1,10,10.10.10.1,255.255.255.255
Como vocês podem observar isso são exemplos e vocês podem adaptar conforme sua necessidade e as solicitações que são exigidas pelas diferentes áreas de sua empresa. Todo o desenvolvimento de nossa automação também é muito co-relacionada com a estrutura de pastas e arquivos que vamos utilizar dentro do Ansible, portanto segue a estrutura que estou utilizando para esse exemplo.
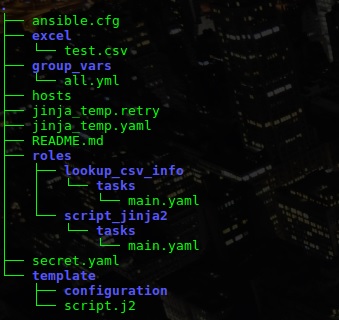
Uma outra informação diferente dos exemplos citados em nossos posts sobre Ansible, é que estou criando como fictício todos esses roteadores em nosso arquivo de inventário ( ./hosts ), para que nosso exemplo seja mais robusto e obviamente no final de nosso exemplo irei demonstrar como aplicar as configurações. Segue meu inventário criado para esse exemplo:
[routers-client]
R1 ansible_host=192.168.0.22
R2 ansible_host=192.168.0.23
R31 ansible_host=192.168.0.24
R5 ansible_host=192.168.0.25
R6 ansible_host=192.168.0.26
Tendo como base essas informações vamos trabalhar com um módulo que Ansible oferece que é de executar um “ lookup ” dentro de um arquivo ( .csv ). Para que nosso código seja mais estruturado minha playbook principal irá chamar minha “ role ” definida como ( ./lookup_csv_info.yaml ).
---
- name: JINJA AND CSVFILE
hosts: all
gather_facts: no
connection: local
tasks:
- name: OBTAIN LOGIN CREDENTIALS
include_vars: secret.yaml
- name: LOOKUP IN CSV FILE
include_role:
name: lookup_csv_info
when: ./excel/test.csv is defined
Talvez vocês devem estar se perguntando o porque utilizar “ roles ” dentro desse código? De fato a funcionalidade role é muito utilizada no sentido de trazer mais dinamismo, funcionalidade e flexibilidade para seu código, pois eles podem se tornar difíceis de gerenciar e difíceis de manter com um único arquivo. As roles permitem que você crie playbooks mínimas que, em seguida, busque uma estrutura de diretório para determinar as etapas de configurações reais que precisam executar, bem como proceder para as próximas roles se anterior foi executada/validada da forma correta.
Seguindo essa linha de raciocínio, demostro agora a playbook específica que irá pesquisar todas as informações dentro de nosso arquivo ( .csv ). Ressalto, que em nosso arquivo temos mais informações do que de fato existem ( hostnames ) nosso arquivo de ( ./hosts ), ou seja, estamos pesquisando em nossa planilha se existem elementos que coincidem com nosso inventário.
---
- name: GET VARIABLES FROM CSVFILE
set_fact:
vars_dict:
DHCP: "{{ lookup('csvfile', '{{ inventory_hostname }} file=./excel/test.csv col=1 delimiter=,') }}"
dhcp_exclude1_start: "{{ lookup('csvfile', '{{ inventory_hostname }} file=./excel/test.csv col=2 delimiter=,') }}"
dhcp_exclude1_end: "{{ lookup('csvfile', '{{ inventory_hostname }} file=./excel/test.csv col=3 delimiter=,') }}"
dhcp_network: "{{ lookup('csvfile', '{{ inventory_hostname }} file=./excel/test.csv col=4 delimiter=,') }}"
dhcp_netmask: "{{ lookup('csvfile', '{{ inventory_hostname }} file=./excel/test.csv col=5 delimiter=,') }}"
dhcp_gateway: "{{ lookup('csvfile', '{{ inventory_hostname }} file=./excel/test.csv col=6 delimiter=,') }}"
new_hostname: "{{ lookup('csvfile', '{{ inventory_hostname }} file=./excel/test.csv col=7 delimiter=,') }}"
id_loopback: "{{ lookup('csvfile', '{{ inventory_hostname }} file=./excel/test.csv col=8 delimiter=,') }}"
ip_loopback: "{{ lookup('csvfile', '{{ inventory_hostname }} file=./excel/test.csv col=9 delimiter=,') }}"
mask_loopback: "{{ lookup('csvfile', '{{ inventory_hostname }} file=./excel/test.csv col=10 delimiter=,') }}"
with_items: "{{ inventory_hostname }}"
Para que possamos ver que as informações estão sendo capturadas vamos colocar uma task contendo debug de uma variável para observar o comportamento. Essa variável em nosso caso é ” var_dict ” onde se tem todo o ” dicionário ” com os valores populados de cada elemento. Para adicionar essa validação foi inserido o comando:
- debug: var={{'vars_dict'}}
Desta forma temos esse output e a confirmação que os dados estão sendo populados corretamente.

Acredito que vocês observaram que temos todos os elementos que foram lidos/capturados baseado em cada coluna de nosso arquivo ( .csv ) comparado ao nosso inventário em uma única “ task “. Porquê?
Isso está relacionado justamente com ” loops ” que podemos criar dentro de nossas “ tasks “, fazendo com que ele faça a mesma tarefa diversas vezes baseado no requisito que estamos utilizando. Para nosso exemplo estou usando a variável “ {{ inventory_hostname }} “, justamente para que ela pesquise no arquivo todos os roteadores expostos no arquivo ( ./hosts ). Essa função pode ser observada através do ” with_items: “.
Espero que vocês tenham gostado e no próximo post vou detalhar como trabalhar com esse dados.

Abs,
Rodrigo